| 撰寫/攝影 | CH.Tseng |
| 部落格 | https://chtseng.wordpress.com/ |
| https://www.facebook.com/chenghsun.tseng |
- Review並重新組合或調整model架構。
- 將資料進行正規化,如L1/L2 regularization。
- 使用dropout技術。
- 使用Data augmentation(資料增強)技術。
dropout技術在之前已介紹並實際應用過,在此所要介紹的是Data augmentation。不同於Dropout透過丟棄一定比例的神經元以模擬不同的dataset,Data augmentation則是從既有的dataset中產生出更多的資料讓系統去學習,說坦白一點,是創造更多的「假」資料,來彌補我們資料不足的缺憾。
雖然是假的資料,但也是從原始資料內容修改產生的,因此Data augmentation經過證實的確可解決資料不足的困境並提昇系統訓練的準確率哦!我們來看看要怎麼使用它。
Data augmentation原理
一張圖片經過旋轉、調整大小、比例尺寸,或者改變亮度色溫、翻轉等處理後,我們人眼仍能辨識出來是相同的相片,但是對機器來說那可是完全不同的新圖像了,因此, Data augmentation就是將dataset中既有的圖片予以修改變形,以創造出更多的圖片來讓機器學習,彌補資料量不足的困擾。
Keras透過ImageDataGenerator class提供Data augmentation相關的功能,如:
- 資料的正規化normalization:可針對Sample-wise(每次取樣的sample batch)或Feature-wise(整體的dataset)
- 資料白化(Whitening)處理:提供ZCA Whitening處理。(Whitening是一種將資料去冗餘的技術)
- 影像處理:翻轉、旋轉、切裁、放大縮小、偏移…等。
更詳細的參數使用請參考https://keras.io/preprocessing/image/。
如何使用Data augmentation
在Keras使用Data augmentation的流程是:
1.載入class:
2.初始化ImageDataGenerator物件,並定義其參數:
3.產生不同的圖形,以下分成兩種狀況來說明:
A)想要產生圖形檔到disk:
- 例如要從某張相片產生10張檔名開頭為cat的jpg圖片,並儲存到目錄preview中:
B)想要在訓練時邊產生圖形:
這又分兩種情況,一種是dataset已載入memory,另一種是dataset放在某實體目錄中尚未讀入。
- dataset已載入memory:
- dataset位在data/train目錄下:
Data augmentation的效果
下方範例為讀入一張圖片,然後透過Data augmentation來產生不同的圖片為例,您可以同步開啟https://github.com/ch-tseng/data-augmentation-Keras/blob/master/DataAugmentation-1.ipynb 來檢視其效果
- 載入相關class及module

- 指定一張相片

- 讀入指定相片:
使用opencv讀入圖片,由於opencv預設格式為BGR,因此需用cvtColor轉為RGB格式。

- 顯示圖片及其資料維度:
由於我們是load單張圖片而非array,因此需要修改其dimention,在前方加入ID項次。


- 定義相關參數:
您可以看到下方的ImageDataGenerator參數值有rotation、shift、shear、flip、zoom、fill_mode…等,從字義上即可瞭解其圖形效果,相關詳細參數說明請參考:https://keras.io/preprocessing/image/

- 經由augmentation產生各種圖形:
datagen.flow會依據指定參數產生各式圖形,您可以輸入一個圖形陣列或本範例一樣的單張圖片。


- Review並重新組合或調整model架構。
- 將資料進行正規化,如L1/L2 regularization。
- 使用dropout技術。
- 使用Data augmentation(資料增強)技術。
dropout技術在之前已介紹並實際應用過,在此所要介紹的是Data augmentation。不同於Dropout透過丟棄一定比例的神經元以模擬不同的dataset,Data augmentation則是從既有的dataset中產生出更多的資料讓系統去學習,說坦白一點,是創造更多的「假」資料,來彌補我們資料不足的缺憾。
雖然是假的資料,但也是從原始資料內容修改產生的,因此Data augmentation經過證實的確可解決資料不足的困境並提昇系統訓練的準確率哦!我們來看看要怎麼使用它。
Data augmentation原理
一張圖片經過旋轉、調整大小、比例尺寸,或者改變亮度色溫、翻轉等處理後,我們人眼仍能辨識出來是相同的相片,但是對機器來說那可是完全不同的新圖像了,因此, Data augmentation就是將dataset中既有的圖片予以修改變形,以創造出更多的圖片來讓機器學習,彌補資料量不足的困擾。
Keras透過ImageDataGenerator class提供Data augmentation相關的功能,如:
- 資料的正規化normalization:可針對Sample-wise(每次取樣的sample batch)或Feature-wise(整體的dataset)
- 資料白化(Whitening)處理:提供ZCA Whitening處理。(Whitening是一種將資料去冗餘的技術)
- 影像處理:翻轉、旋轉、切裁、放大縮小、偏移…等。
更詳細的參數使用請參考https://keras.io/preprocessing/image/。
如何使用Data augmentation
在Keras使用Data augmentation的流程是:
- 載入class:
from keras.preprocessing.image import ImageDataGenerator
- 初始化ImageDataGenerator物件,並定義其參數:
datagen = ImageDataGenerator(
zca_whitening=False,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode=’nearest’)
- 產生不同的圖形,以下分成兩種狀況來說明:
A)想要產生圖形檔到disk:
- 例如要從某張相片產生10張檔名開頭為cat的jpg圖片,並儲存到目錄preview中:
img = cv2.imread(“test1.jpg”)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#格式必須為:(sample數, channels, height, width)
img = img.reshape((1,) + img.shape)
for batch in datagen.flow(img, batch_size=10,
save_to_dir=’preview’, save_prefix=’cat’, save_format=’jpeg’)
B)想要在訓練時邊產生圖形:
這又分兩種情況,一種是dataset已載入memory,另一種是dataset放在某實體目錄中尚未讀入。
- dataset已載入memory:
datagen.fit(trainData)
train_history = model.fit_generator(train_datagen.flow(trainData,
trainLabels_hot, batch_size=64),
steps_per_epoch=round(len(trainData)/64),
epochs=50, validation_data=(valiData, valiLabels_hot))
- dataset位在data/train目錄下:
trainData = train_datagen.flow_from_directory(
“data/train”,
target_size=(150, 150), #可以在此指定要rescale的尺寸
batch_size=64,
class_mode=’binary’)
model.fit_generator(
trainData,
steps_per_epoch= round(len(trainData)/64),
epochs=50,
validation_data=(valiData, valiLabels_hot) )
Data augmentation的效果
下方範例為讀入一張圖片,然後透過Data augmentation來產生不同的圖片為例,您可以同步開啟https://github.com/ch-tseng/data-augmentation-Keras/blob/master/DataAugmentation-1.ipynb 來檢視其效果
- 載入相關class及module
import cv2
from matplotlib import pyplot as plt
%matplotlib inline
from pylab import rcParams
rcParams[‘figure.figsize’] = 15, 15
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img

- 指定一張相片
imgForTest = “../test1.jpg”

- 讀入指定相片:
使用opencv讀入圖片,由於opencv預設格式為BGR,因此需用cvtColor轉為RGB格式。
img = cv2.imread(imgForTest)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)

- 顯示圖片及其資料維度:
由於我們是load單張圖片而非array,因此需要修改其dimention,在前方加入ID項次。
plt.imshow(img)
print(img.shape)
img = img.reshape((1,) + img.shape)
print(img.shape)


- 定義相關參數:
您可以看到下方的ImageDataGenerator參數值有rotation、shift、shear、flip、zoom、fill_mode…等,從字義上即可瞭解其圖形效果,相關詳細參數說明請參考:https://keras.io/preprocessing/image/
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode=’nearest’)

- 經由augmentation產生各種圖形:
datagen.flow會依據指定參數產生各式圖形,您可以輸入一個圖形陣列或本範例一樣的單張圖片。
i = 0
for batch in datagen.flow(img, batch_size=10,
save_to_dir=’small-2000/preview’, save_prefix=’cat’, save_format=’jpeg’):
plt.subplot(5,4,1 + i)
plt.axis(“off”)
augImage = batch[0]
augImage = augImage.astype(‘float32’)
augImage /= 255
plt.imshow(augImage)
i += 1
if i > 19:
break

同樣的,一張小狗的照片可以產生這麼多的新圖片:https://github.com/ch-tseng/data-augmentation-Keras/blob/master/dogcat-augmentation.ipynb

model.fit與model.fit_generator
注意在使用Data augmentation時,進行訓練所使用的model.fit須改為model.fit_generator才讓系統on-fly的產生新圖像提供訓練使用。model.fit與model.fit_generator這兩個指令都是for相同的訓練用途,但使用時機大有不同:
- model.fit 適用於Dataset已ready,不需再進行任何預處理可直接使用。
- model.fit_generator 適用於Dataset尚未ready,需要在每批次訓練先進行預處理(或產生)。
由於model.fit_generator在每批次訓練前才on demand或on-the-fly處理或產生data,因此能比較有效率的應用在一些硬體資源不太足夠的機器上(例如RAM僅有8G然而dataset卻有1TB的情況),model.fit_generator可避免load整個dataset,只需要在每批次訓練前on-demand產生需要數量的data。
那麼,我們要如何定義要經由Data augmentation產生多少資料呢?最簡單的方式是透過參數samples_per_epoch,該參數定義每次epoch要產生多少sample data(亦即系統在每個epoch所能看到的資料數量)。在下方的例子中,我們設定為training dataset的2倍數量。
如此一來,如果我們的dataset只有1,000張,但透過augmentation實際上訓練的數量可擴增到2,000張,是不是很方便呢?
我們也可以用另一種方式,不先給予total的training數目而是指定每個epoch要分成幾個batch來run(參數steps_per_epoch),以及每次batch所要提取的sample數目為多少?(參數batch size),因此,一個epoch所train的dataset數目就是steps_per_epoch乘上batch_size。下面的例子同樣每epoch會run 2倍於目前的dataset數量。(注意:nb_epoch 參數自Keras 2.0開始已被epoch參數取代)
實際應用
接下來我以之前作過的「使用CNN 識別辦公區狀態」為例子,該dataset的資訊如下:
- 格式:jpeg,224×224 pixels
- 相片日期:2017/04~2017/09
- 分類:共有17種categories,每個category有70張相片,共1,190張。
每張圖片依如下分為四個區域並給予label:由左上角本人座位開始順時間方向,1代表有人,0代表無人,亦即該區只要有人出現該區便視為1,因此,下面的兩張圖皆會被label為1-1-0-1。
 |
 |
若剛好有人橫跨兩個區域,則視其在那一區域佔的比例較多來決定,例如:




- Review並重新組合或調整model架構。
- 將資料進行正規化,如L1/L2 regularization。
- 使用dropout技術。
- 使用Data augmentation(資料增強)技術。
dropout技術在之前已介紹並實際應用過,在此所要介紹的是Data augmentation。不同於Dropout透過丟棄一定比例的神經元以模擬不同的dataset,Data augmentation則是從既有的dataset中產生出更多的資料讓系統去學習,說坦白一點,是創造更多的「假」資料,來彌補我們資料不足的缺憾。
雖然是假的資料,但也是從原始資料內容修改產生的,因此Data augmentation經過證實的確可解決資料不足的困境並提昇系統訓練的準確率哦!我們來看看要怎麼使用它。
Data augmentation原理
一張圖片經過旋轉、調整大小、比例尺寸,或者改變亮度色溫、翻轉等處理後,我們人眼仍能辨識出來是相同的相片,但是對機器來說那可是完全不同的新圖像了,因此, Data augmentation就是將dataset中既有的圖片予以修改變形,以創造出更多的圖片來讓機器學習,彌補資料量不足的困擾。
Keras透過ImageDataGenerator class提供Data augmentation相關的功能,如:
- 資料的正規化normalization:可針對Sample-wise(每次取樣的sample batch)或Feature-wise(整體的dataset)
- 資料白化(Whitening)處理:提供ZCA Whitening處理。(Whitening是一種將資料去冗餘的技術)
- 影像處理:翻轉、旋轉、切裁、放大縮小、偏移…等。
更詳細的參數使用請參考https://keras.io/preprocessing/image/。
如何使用Data augmentation
在Keras使用Data augmentation的流程是:
- 載入class:
from keras.preprocessing.image import ImageDataGenerator
- 初始化ImageDataGenerator物件,並定義其參數:
datagen = ImageDataGenerator(
zca_whitening=False,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode=’nearest’)
- 產生不同的圖形,以下分成兩種狀況來說明:
A)想要產生圖形檔到disk:
- 例如要從某張相片產生10張檔名開頭為cat的jpg圖片,並儲存到目錄preview中:
img = cv2.imread(“test1.jpg”)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#格式必須為:(sample數, channels, height, width)
img = img.reshape((1,) + img.shape)
for batch in datagen.flow(img, batch_size=10,
save_to_dir=’preview’, save_prefix=’cat’, save_format=’jpeg’)
B)想要在訓練時邊產生圖形:
這又分兩種情況,一種是dataset已載入memory,另一種是dataset放在某實體目錄中尚未讀入。
- dataset已載入memory:
datagen.fit(trainData)
train_history = model.fit_generator(train_datagen.flow(trainData,
trainLabels_hot, batch_size=64),
steps_per_epoch=round(len(trainData)/64),
epochs=50, validation_data=(valiData, valiLabels_hot))
- dataset位在data/train目錄下:
trainData = train_datagen.flow_from_directory(
“data/train”,
target_size=(150, 150), #可以在此指定要rescale的尺寸
batch_size=64,
class_mode=’binary’)
model.fit_generator(
trainData,
steps_per_epoch= round(len(trainData)/64),
epochs=50,
validation_data=(valiData, valiLabels_hot) )
Data augmentation的效果
下方範例為讀入一張圖片,然後透過Data augmentation來產生不同的圖片為例,您可以同步開啟https://github.com/ch-tseng/data-augmentation-Keras/blob/master/DataAugmentation-1.ipynb 來檢視其效果
- 載入相關class及module
import cv2
from matplotlib import pyplot as plt
%matplotlib inline
from pylab import rcParams
rcParams[‘figure.figsize’] = 15, 15
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
- 指定一張相片
imgForTest = “../test1.jpg”
- 讀入指定相片:
使用opencv讀入圖片,由於opencv預設格式為BGR,因此需用cvtColor轉為RGB格式。
img = cv2.imread(imgForTest)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
- 顯示圖片及其資料維度:
由於我們是load單張圖片而非array,因此需要修改其dimention,在前方加入ID項次。
plt.imshow(img)
print(img.shape)
img = img.reshape((1,) + img.shape)
print(img.shape)
- 定義相關參數:
您可以看到下方的ImageDataGenerator參數值有rotation、shift、shear、flip、zoom、fill_mode…等,從字義上即可瞭解其圖形效果,相關詳細參數說明請參考:https://keras.io/preprocessing/image/
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode=’nearest’)
- 經由augmentation產生各種圖形:
datagen.flow會依據指定參數產生各式圖形,您可以輸入一個圖形陣列或本範例一樣的單張圖片。
i = 0
for batch in datagen.flow(img, batch_size=10,
save_to_dir=’small-2000/preview’, save_prefix=’cat’, save_format=’jpeg’):
plt.subplot(5,4,1 + i)
plt.axis(“off”)
augImage = batch[0]
augImage = augImage.astype(‘float32’)
augImage /= 255
plt.imshow(augImage)
i += 1
if i > 19:
break
同樣的,一張小狗的照片可以產生這麼多的新圖片:https://github.com/ch-tseng/data-augmentation-Keras/blob/master/dogcat-augmentation.ipynb

model.fit與model.fit_generator
注意在使用Data augmentation時,進行訓練所使用的model.fit須改為model.fit_generator才讓系統on-fly的產生新圖像提供訓練使用。model.fit與model.fit_generator這兩個指令都是for相同的訓練用途,但使用時機大有不同:
- model.fit 適用於Dataset已ready,不需再進行任何預處理可直接使用。
- model.fit_generator 適用於Dataset尚未ready,需要在每批次訓練先進行預處理(或產生)。
由於model.fit_generator在每批次訓練前才on demand或on-the-fly處理或產生data,因此能比較有效率的應用在一些硬體資源不太足夠的機器上(例如RAM僅有8G然而dataset卻有1TB的情況),model.fit_generator可避免load整個dataset,只需要在每批次訓練前on-demand產生需要數量的data。
那麼,我們要如何定義要經由Data augmentation產生多少資料呢?最簡單的方式是透過參數samples_per_epoch,該參數定義每次epoch要產生多少sample data(亦即系統在每個epoch所能看到的資料數量)。在下方的例子中,我們設定為training dataset的2倍數量。
epochs = 15
batch_size = 32
train_history = model.fit_generator(
train_datagen.flow(trainData_normalize, trainLabels_hot, batch_size=batch_size),
samples_per_epoch=(len(trainData)*2), nb_epoch=epochs,
validation_data=(valiData_normalize, valiLabels_hot))
如此一來,如果我們的dataset只有1,000張,但透過augmentation實際上訓練的數量可擴增到2,000張,是不是很方便呢?
我們也可以用另一種方式,不先給予total的training數目而是指定每個epoch要分成幾個batch來run(參數steps_per_epoch),以及每次batch所要提取的sample數目為多少?(參數batch size),因此,一個epoch所train的dataset數目就是steps_per_epoch乘上batch_size。下面的例子同樣每epoch會run 2倍於目前的dataset數量。(注意:nb_epoch 參數自Keras 2.0開始已被epoch參數取代)
epochs = 50
batch_size = 32
steps_per_epoch=int((len(trainData)*2)/batch_size)
train_history = model.fit_generator(
train_datagen.flow(trainData_normalize, trainLabels_hot, atch_size=batch_size),
steps_per_epoch=steps_per_epoch, epochs=epochs,
validation_data=(valiData_normalize, valiLabels_hot))
實際應用
接下來我以之前作過的「使用CNN 識別辦公區狀態」為例子,該dataset的資訊如下:
- 格式:jpeg,224×224 pixels
- 相片日期:2017/04~2017/09
- 分類:共有17種categories,每個category有70張相片,共1,190張。
每張圖片依如下分為四個區域並給予label:由左上角本人座位開始順時間方向,1代表有人,0代表無人,亦即該區只要有人出現該區便視為1,因此,下面的兩張圖皆會被label為1-1-0-1。
 |
 |
若剛好有人橫跨兩個區域,則視其在那一區域佔的比例較多來決定,例如:




總計會有17種情況,因此所有相片會被歸屬於17個不同的labels(Categories)。每個category舉例一張如下(後方的藍色數字代表其label的代碼):
| 0-0-0-0(11) | 1-0-0-0(7) | 0-1-0-0(14) |
 |
 |
 |
| 0-0-1-0(9) | 0-0-0-1(12) | 1-1-0-0(6) |
 |
 |
 |
| 0-1-1-0(16) | 0-0-1-1(1) | 1-0-1-0(8) |
 |
 |
 |
| 0-1-0-1(2) | 1-0-0-1(4) | 1-1-1-0(13) |
 |
 |
 |
| 0-1-1-1(3) | 1-0-1-1(0) | 1-1-0-1(15) |
 |
 |
 |
| 1-1-1-1(10) | Dark(5) | |
 |
 |
- Review並重新組合或調整model架構。
- 將資料進行正規化,如L1/L2 regularization。
- 使用dropout技術。
- 使用Data augmentation(資料增強)技術。
dropout技術在之前已介紹並實際應用過,在此所要介紹的是Data augmentation。不同於Dropout透過丟棄一定比例的神經元以模擬不同的dataset,Data augmentation則是從既有的dataset中產生出更多的資料讓系統去學習,說坦白一點,是創造更多的「假」資料,來彌補我們資料不足的缺憾。
雖然是假的資料,但也是從原始資料內容修改產生的,因此Data augmentation經過證實的確可解決資料不足的困境並提昇系統訓練的準確率哦!我們來看看要怎麼使用它。
Data augmentation原理
一張圖片經過旋轉、調整大小、比例尺寸,或者改變亮度色溫、翻轉等處理後,我們人眼仍能辨識出來是相同的相片,但是對機器來說那可是完全不同的新圖像了,因此, Data augmentation就是將dataset中既有的圖片予以修改變形,以創造出更多的圖片來讓機器學習,彌補資料量不足的困擾。
Keras透過ImageDataGenerator class提供Data augmentation相關的功能,如:
- 資料的正規化normalization:可針對Sample-wise(每次取樣的sample batch)或Feature-wise(整體的dataset)
- 資料白化(Whitening)處理:提供ZCA Whitening處理。(Whitening是一種將資料去冗餘的技術)
- 影像處理:翻轉、旋轉、切裁、放大縮小、偏移…等。
更詳細的參數使用請參考https://keras.io/preprocessing/image/。
如何使用Data augmentation
在Keras使用Data augmentation的流程是:
- 載入class:
from keras.preprocessing.image import ImageDataGenerator
- 初始化ImageDataGenerator物件,並定義其參數:
datagen = ImageDataGenerator(
zca_whitening=False,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode=’nearest’)
- 產生不同的圖形,以下分成兩種狀況來說明:
A)想要產生圖形檔到disk:
- 例如要從某張相片產生10張檔名開頭為cat的jpg圖片,並儲存到目錄preview中:
img = cv2.imread(“test1.jpg”)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#格式必須為:(sample數, channels, height, width)
img = img.reshape((1,) + img.shape)
for batch in datagen.flow(img, batch_size=10,
save_to_dir=’preview’, save_prefix=’cat’, save_format=’jpeg’)
B)想要在訓練時邊產生圖形:
這又分兩種情況,一種是dataset已載入memory,另一種是dataset放在某實體目錄中尚未讀入。
- dataset已載入memory:
datagen.fit(trainData)
train_history = model.fit_generator(train_datagen.flow(trainData,
trainLabels_hot, batch_size=64),
steps_per_epoch=round(len(trainData)/64),
epochs=50, validation_data=(valiData, valiLabels_hot))
- dataset位在data/train目錄下:
trainData = train_datagen.flow_from_directory(
“data/train”,
target_size=(150, 150), #可以在此指定要rescale的尺寸
batch_size=64,
class_mode=’binary’)
model.fit_generator(
trainData,
steps_per_epoch= round(len(trainData)/64),
epochs=50,
validation_data=(valiData, valiLabels_hot) )
Data augmentation的效果
下方範例為讀入一張圖片,然後透過Data augmentation來產生不同的圖片為例,您可以同步開啟https://github.com/ch-tseng/data-augmentation-Keras/blob/master/DataAugmentation-1.ipynb 來檢視其效果
- 載入相關class及module
import cv2
from matplotlib import pyplot as plt
%matplotlib inline
from pylab import rcParams
rcParams[‘figure.figsize’] = 15, 15
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
- 指定一張相片
imgForTest = “../test1.jpg”
- 讀入指定相片:
使用opencv讀入圖片,由於opencv預設格式為BGR,因此需用cvtColor轉為RGB格式。
img = cv2.imread(imgForTest)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
- 顯示圖片及其資料維度:
由於我們是load單張圖片而非array,因此需要修改其dimention,在前方加入ID項次。
plt.imshow(img)
print(img.shape)
img = img.reshape((1,) + img.shape)
print(img.shape)
- 定義相關參數:
您可以看到下方的ImageDataGenerator參數值有rotation、shift、shear、flip、zoom、fill_mode…等,從字義上即可瞭解其圖形效果,相關詳細參數說明請參考:https://keras.io/preprocessing/image/
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode=’nearest’)
- 經由augmentation產生各種圖形:
datagen.flow會依據指定參數產生各式圖形,您可以輸入一個圖形陣列或本範例一樣的單張圖片。
i = 0
for batch in datagen.flow(img, batch_size=10,
save_to_dir=’small-2000/preview’, save_prefix=’cat’, save_format=’jpeg’):
plt.subplot(5,4,1 + i)
plt.axis(“off”)
augImage = batch[0]
augImage = augImage.astype(‘float32’)
augImage /= 255
plt.imshow(augImage)
i += 1
if i > 19:
break
同樣的,一張小狗的照片可以產生這麼多的新圖片:https://github.com/ch-tseng/data-augmentation-Keras/blob/master/dogcat-augmentation.ipynb
model.fit與model.fit_generator
注意在使用Data augmentation時,進行訓練所使用的model.fit須改為model.fit_generator才讓系統on-fly的產生新圖像提供訓練使用。model.fit與model.fit_generator這兩個指令都是for相同的訓練用途,但使用時機大有不同:
- model.fit 適用於Dataset已ready,不需再進行任何預處理可直接使用。
- model.fit_generator 適用於Dataset尚未ready,需要在每批次訓練先進行預處理(或產生)。
由於model.fit_generator在每批次訓練前才on demand或on-the-fly處理或產生data,因此能比較有效率的應用在一些硬體資源不太足夠的機器上(例如RAM僅有8G然而dataset卻有1TB的情況),model.fit_generator可避免load整個dataset,只需要在每批次訓練前on-demand產生需要數量的data。
那麼,我們要如何定義要經由Data augmentation產生多少資料呢?最簡單的方式是透過參數samples_per_epoch,該參數定義每次epoch要產生多少sample data(亦即系統在每個epoch所能看到的資料數量)。在下方的例子中,我們設定為training dataset的2倍數量。
epochs = 15
batch_size = 32
train_history = model.fit_generator(
train_datagen.flow(trainData_normalize, trainLabels_hot, batch_size=batch_size),
samples_per_epoch=(len(trainData)*2), nb_epoch=epochs,
validation_data=(valiData_normalize, valiLabels_hot))
如此一來,如果我們的dataset只有1,000張,但透過augmentation實際上訓練的數量可擴增到2,000張,是不是很方便呢?
我們也可以用另一種方式,不先給予total的training數目而是指定每個epoch要分成幾個batch來run(參數steps_per_epoch),以及每次batch所要提取的sample數目為多少?(參數batch size),因此,一個epoch所train的dataset數目就是steps_per_epoch乘上batch_size。下面的例子同樣每epoch會run 2倍於目前的dataset數量。(注意:nb_epoch 參數自Keras 2.0開始已被epoch參數取代)
epochs = 50
batch_size = 32
steps_per_epoch=int((len(trainData)*2)/batch_size)
train_history = model.fit_generator(
train_datagen.flow(trainData_normalize, trainLabels_hot, atch_size=batch_size),
steps_per_epoch=steps_per_epoch, epochs=epochs,
validation_data=(valiData_normalize, valiLabels_hot))
實際應用
接下來我以之前作過的「使用CNN 識別辦公區狀態」為例子,該dataset的資訊如下:
- 格式:jpeg,224×224 pixels
- 相片日期:2017/04~2017/09
- 分類:共有17種categories,每個category有70張相片,共1,190張。
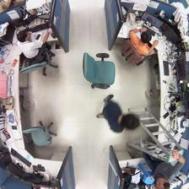
每張圖片依如下分為四個區域並給予label:由左上角本人座位開始順時間方向,1代表有人,0代表無人,亦即該區只要有人出現該區便視為1,因此,下面的兩張圖皆會被label為1-1-0-1。
|
|
若剛好有人橫跨兩個區域,則視其在那一區域佔的比例較多來決定,例如:
總計會有17種情況,因此所有相片會被歸屬於17個不同的labels(Categories)。每個category舉例一張如下(後方的藍色數字代表其label的代碼):
| 0-0-0-0(11) | 1-0-0-0(7) | 0-1-0-0(14) |
 |
 |
 |
| 0-0-1-0(9) | 0-0-0-1(12) | 1-1-0-0(6) |
 |
 |
 |
| 0-1-1-0(16) | 0-0-1-1(1) | 1-0-1-0(8) |
 |
 |
 |
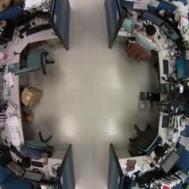
| 0-1-0-1(2) | 1-0-0-1(4) | 1-1-1-0(13) |
 |
 |
 |
| 0-1-1-1(3) | 1-0-1-1(0) | 1-1-0-1(15) |
 |
 |
 |
| 1-1-1-1(10) | Dark(5) | |
 |
 |
比較有否使用Data Augmentation的差異
未使用Data Augmentation
由於此dataset總圖片張數僅有1,190張,因此我們打算比較看看加入Data Augmentation功能是否能提昇其準確率。因為時間因素,我們僅訓練15 epoches,首先,是未使用data augmentation的結果:



F1-score成績僅為0.69。
使用Data Augmentation
接下來我們看看加入data augmentation的效果。在下方,我們增加一個調整曝光值的function,讓data augmentation能產生各種不同亮度的相片作為新圖片來使用。



使用Test dataset測試結果,F1-score成績為0.85,發現使用Data augmentation讓成績大幅提昇了23%。
註:上述的程式碼已上傳Github,您可參考下方的連結:
1. 未使用Data augmentation的程式: https://github.com/ch-tseng/data-augmentation-Keras/blob/master/CNN-Meetingroom-Augmentation-No.ipynb
2. 使用Data augmentation的程式: https://github.com/ch-tseng/data-augmentation-Keras/blob/master/CNN-Meetingroom-Augmentation-2.ipynb
想了解更多CH.Tseng,可以點此連結 瀏覽更多文章喔~















